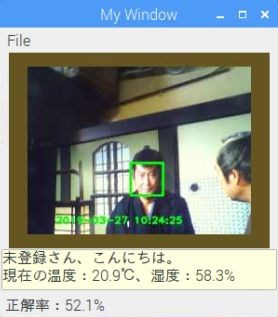
webカメラ画像の場合
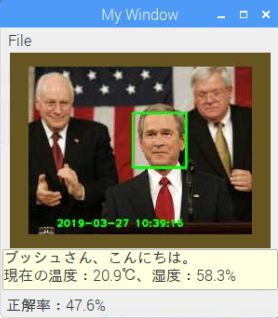
jpegファイル画像の場合
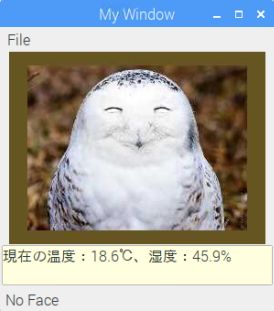
顔無jpegファイル画像の場合
前回作成したTensorFlowを使用した顔認識プログラム(face_recog_pi.py)を"wxPython"と云うライブラリを使ってGUI表示するように雑誌インターフェース(2017/3)の特集記事とソースファイル(main.py)を参考に作ってみた。
"wxPython"の最新版(4.0.4)はソースしかなく、参考サイトの手順でビルドしてから導入。(pythonのバージョンは3.5のまま)
ビルドは、参考サイトの記述に『This will take a while, anywhere from a few hours, to 18+ hours on a Pi zero. 』と書かれていたので、寝る前に実行させて起きたら出来上がっている感じでした。
また、音声出力もさせるため日本語文字から音声に変換する"OpenJTalk"の最新版(1.11)も参考サイトの手順でソースから作成し導入。
こちらは、さほど時間は掛からなかったが、コンパイル中に"WARNING"メッセージが沢山出た。(出来上がった物の実行には影響出ていない様だが…)
webカメラ画像の場合 |
jpegファイル画像の場合 |
顔無jpegファイル画像の場合 |
プログラムは前回作成した顔認識と今回参考の雑誌記事を掛け合わせて作ったが、幾つか小細工が必要になった。
【その1】顔検出枠サイズと認識精度
OpenCVでの顔検出時、miniSizeパラメータの値によってその後のTensorFlowによる認識精度が変わることがテスト中に分かり、色々試して最適な検出結果が得られるようにした。(画像内に1つの顔でもminiSizeの値によって検出枠の値が変わる事が色々試して分かった)
:
:
minsz = 50 # 最初に、小さい値で検出顔枠サイズ情報を得る
facerect = self.cascade_f.detectMultiScale(image_gray, scaleFactor=1.08, minNeighbors=2, minSize=(minsz, minsz))
image_face = []
if len(facerect) > 0:
maxhw = np.argmax(facerect, axis=0) # 検出した顔枠で最大高さ値を持つ顔枠情報
minsz = facerect[maxhw[2]][2] # 最大顔枠の高さ値をminiSizeとして使い再度顔検出実行
facerect = self.cascade_f.detectMultiScale(image_gray, scaleFactor=1.08, minNeighbors=1, minSize=(minsz, minsz))
:
:
【その2】音声出力と画像表示のズレ
文字から音声に変換して音声出力終了までに4〜5秒掛かって、その後に画像と認識結果が表示されると云う時間差が生じてしまった。そこで、音声ファイルを3分割して、挨拶と温湿度情報の音声は定期的に事前作成しておき、顔認識後、名前の音声出力時に他の2ファイルを続けて出力するようにしてみた。
:
def speech(serif,f):
if serif == '': return
# 音声ファイル作成
# fの値が、null:名前音声作成と音声出力要求、1:挨拶音声作成、2:温湿度情報音声作成
audio_wav = "speech" + f + ".wav"
hts = '/usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice'
dic = '/var/lib/mecab/dic/open_jtalk_dic_utf_8-1.11'
cmd = "open_jtalk -fm 6.0 -g 2.0 -jf 1.5 -m %s -x %s -ow %s" % (hts, dic, audio_wav) # -fm:高音質化、-g:音量増
c = proc.Popen(cmd.split(' '), stdin=proc.PIPE)
c.stdin.write(serif.encode('utf8')) # 音声に変換する文字列
c.stdin.close()
c.wait()
if f == "": # 音声出力処理
wx.adv.Sound.PlaySound("speech.wav") # "名前さん"
sleep(1.1) # 次の挨拶と間が開いてしまうので"wx.adv.SOUND_SYNC"からsleepに変えて調整
wx.adv.Sound.PlaySound("speech1.wav", wx.adv.SOUND_SYNC) # 挨拶
wx.adv.Sound.PlaySound("speech2.wav") # 温湿度情報
:
しかし、まだ2〜3秒ぐらいの時間差が出るので、名前音声作成と音声出力をスレッド処理に変えてみたところ、画像表示直後に音声が出て、良いタイミングになった。
:
self.thread = threading.Thread(target=speech, name="speech", args=(msg,"",))
self.thread.start()
:
【参考】